Generative AI is increasingly becoming a part of researchers’ and analysts’ toolkits and reshaping how we design and deliver our work. But what does this mean for the international development community, particularly evaluators?
A recent VoxDev blog highlights how quickly research and applications of AI are emerging across development economics, from labor markets and education to entrepreneurship and public services. For evaluators, this raises a key question—how can we integrate AI and its applications in ways that enhance the quality of evidence and strengthen its policy relevance rather than simply speeding up workflows?
In this blog, we highlight several examples from 3ie’s work that demonstrate how AI can help unlock new sources and types of data, strengthen evaluation design, analyze larger volumes of data than ever before, and do it faster and more cost-effectively. Ultimately, AI can free up valuable researcher time to imagine more ambitious evaluations and perhaps bring us closer to solving key challenges in international development that were previously deemed insurmountable.
AI for image classification
Value-add: validate/ground truth intervention design, and construct additional covariates and outcome measures
Evaluating the effectiveness of agriculture and aquaculture interventions often requires reliable information about farmland and fishpond characteristics, which can be difficult to capture through surveys alone. AI-based image classification is making it faster and more consistent to identify and measure these characteristics at scale, whether from satellite imagery or ground-level field photographs. In one application, our team is evaluating an intervention that aims to increase food security and household consumption. To build reliable baseline statistics and measure program outcomes, the evaluation required detailed information about fishpond characteristics, including whether ponds exist, contain water, are formally constructed, and appear to be in use. Manually reviewing and classifying thousands of field photographs would be time-consuming and difficult to implement consistently.
How we used AI: To address this, we wrote code that calls the OpenAI API to analyze ground-level field photographs of fishponds, prompting the model to classify each image across a set of structured dimensions, including water visibility, water size, water color, pond structure, and surrounding land conditions, and return the results in a structured output. This served two purposes: validating survey data (e.g., confirming a reported pond exists and appears active) and constructing new covariates and outcome measures from observed pond characteristics. In practice, this meant the evaluation could go beyond survey responses, using AI to systematically verify program implementation and generate richer indicators on aquaculture practices across many sites. This approach reflects a broader set of geospatial and image analysis methods that 3ie is applying to real-world evaluation challenges. For more information on using remotely sensed proxy indicators for social science research, see our Remote Sensing Inventory.
AI for creation of outcome variables from disparate documents
Value-add: generate structured outcome variables on research practices from full-text proposals and publications at scale.
Do research grants actually improve the creation and quality of evidence? To find out, 3ie conducted an impact evaluation comparing hundreds of funded and unfunded proposals between 2009 and 2020. Rather than relying only on publication or citation counts, we wanted to measure richer dimensions of research practice: use of mixed methods, transparency, and stakeholder engagement. Extracting this from full-text proposals and publications at scale would normally mean months of manual coding.
How we used AI: We developed a script that calls the GPT 5 model to extract information from hundreds of documents to generate key outcome variables. Extracting some variables was straightforward (titles, publication year), others required nuanced judgment and classification (whether stakeholder engagement was described, or transparency practices reported). Validation against human annotations showed accuracy of 90-100%, depending on the complexity of the outcome. This enabled the team to scale document analysis that would otherwise have required months of manual work, while maintaining a high level of reliability.
AI for data extraction from transcripts and multilingual text
Value-add: rapidly synthesize large volumes of program documentation and qualitative evidence to inform evaluation design.
Let’s consider another case, in which 3ie needed to evaluate a complex intervention that spanned more than a decade and understand its evolution within a constrained timeline. A large corpus of documentation was available, including evaluation reports, administrative databases, policy documents and briefs, ministry websites, and other institutional records. Traditionally, it would require substantial manual effort to extract insights, classify document types, and identify key activities, theories of change, and other contextual information.
How we used AI: The evaluation team used natural language processing (NLP) to analyze more than 500 pages of text, allowing the rapid structuring and interpretation of program information. In addition to the document review, the team conducted multiple in-person activities with stakeholders, including workshops and individual consultations. An AI-enabled qualitative analysis platform (AILYZE) supported the translation of audio recordings from Spanish to English, transcription from audio to text, and generated discussion summaries across nearly 20 interactions. Together, these tools allowed the team to develop a rigorous, contextually grounded evaluation design within a compressed timeline.
AI for processing large volumes of non-English handwritten text
Value-add: process large volumes of multilingual handwritten administrative records to generate structured time series data on outcomes that would otherwise not be available.
Consider the evaluation of an intervention in which we want to draw on school administrative records. The catch? Hundreds of thousands of semi-structured records exist only in handwritten form. Digitizing them manually would take many months and significant funding. Traditionally, we may decide not to proceed with collecting this data.
How we can use AI: By combining large language models with optical character recognition, we can interpret handwritten non-English text at scale, recognize document context (e.g., whether a column contains a specific range of numeric grades), and convert unstructured image data into clean analysis-ready outputs. This approach, paired with manual review to construct ground-truth versions of each type of document, would enable us to extract records with high confidence at a scale and speed that human reviewers could not. The result would be a high-frequency, student-level panel tracking performance over multiple years—a dataset that enables a far larger population-based analysis than surveys alone could support, and one that wouldn’t exist without AI.
Parting thoughts and words of caution
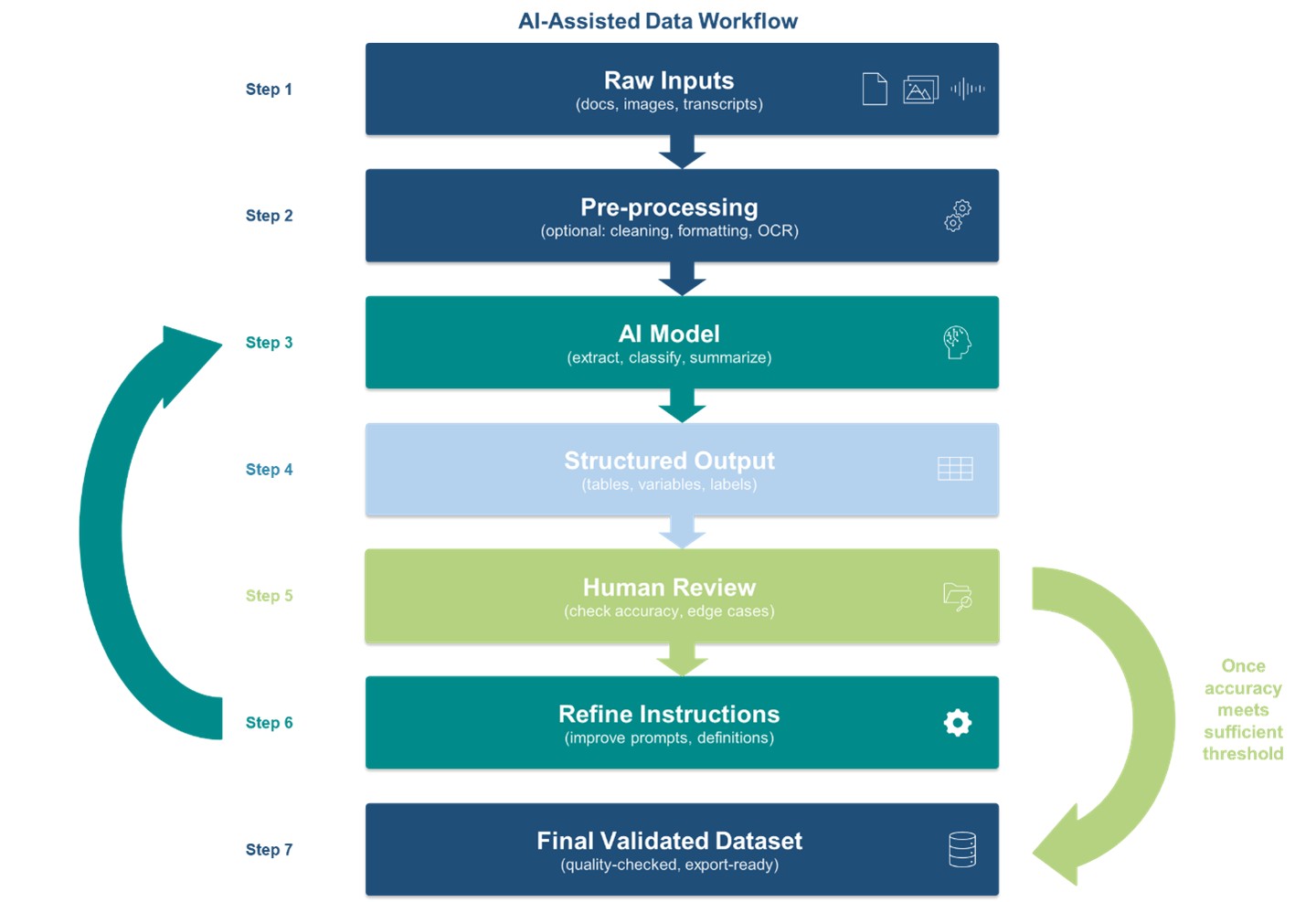
While the value of AI is undeniable, its use in evaluation contexts comes with important caveats. Chief among them is that large language models are not deterministic, meaning that even under strict settings, outputs can vary across runs, and mistakes will occur. In some ways, this mirrors familiar challenges in evaluation methodology, such as measurement error or interrater reliability: just as two data-entry operators might interpret the same handwriting differently, an LLM may not process identical inputs the same way twice. But as with traditional methods, these errors can be identified, quantified, and adjusted for through techniques like fuzzy matching for data cleaning, or systematic human review to establish ground-truth benchmarks.
In fact, the convincing nature of AI outputs makes rigorous oversight more important as there are less obvious cues when something is wrong. Across the projects described here, evaluation teams built in systematic quality checks: for instance, review of all AI-generated transcriptions and summaries to ensure intent is accurately conveyed, and human review of 10-15% of each data extraction output to assess measurement error and identify fields needing additional attention. In parallel, ongoing evaluation work in sensitive domains such as mental health interventions tests both the effectiveness of chatbot-based support and the associated security and risk considerations, including potential harms, bias, and safeguarding challenges.
It's also worth reiterating that the output is only ever as good as the underlying data. In the image classification task, for example, images classified as "NA" (no pond) or with a pond color of "black" initially appeared to be errors, until human reviewers confirmed the photos had simply been taken in the dark. Prompting the model to also generate a plain-language description of each image proved valuable precisely for catching edge cases.
The lesson across all these use cases is the same: AI can dramatically expand what's possible in evaluation, but it demands the same rigor, and arguably more critical thinking than any other method.
*AI was used in the writing and editing of this blog.













