I am often in meetings with staff of implementing agencies in which I say things like ‘a randomised design will allow you to make the strongest conclusions about causality’. So I am not an ‘unrandomista’.
However, from the vantage point of 3ie having funded over 150 studies in the last few years, there are some pitfalls to watch for in order to design and implement randomised controlled trials (RCTs) that lead to better policies and better lives. If we don’t watch out for these, we will just end up wasting the time and money of funders, researchers and the intended beneficiaries.
So here’s my list of top ten things that can go wrong with RCTs. And yes, you will quickly spot that most of these points are not unique to RCTs and could apply to any impact evaluation. But that does not take away from the fact that they still need to be avoided when designing and implementing RCTs.
- Testing things that just don’t work: We have funded impact evaluations in which the technology at the heart of the intervention didn’t work under actual field conditions. We don’t need a half – million dollar impact evaluation to find this out. In such cases, a formative evaluation, which includes small-scale field testing of the technology, should precede an RCT.
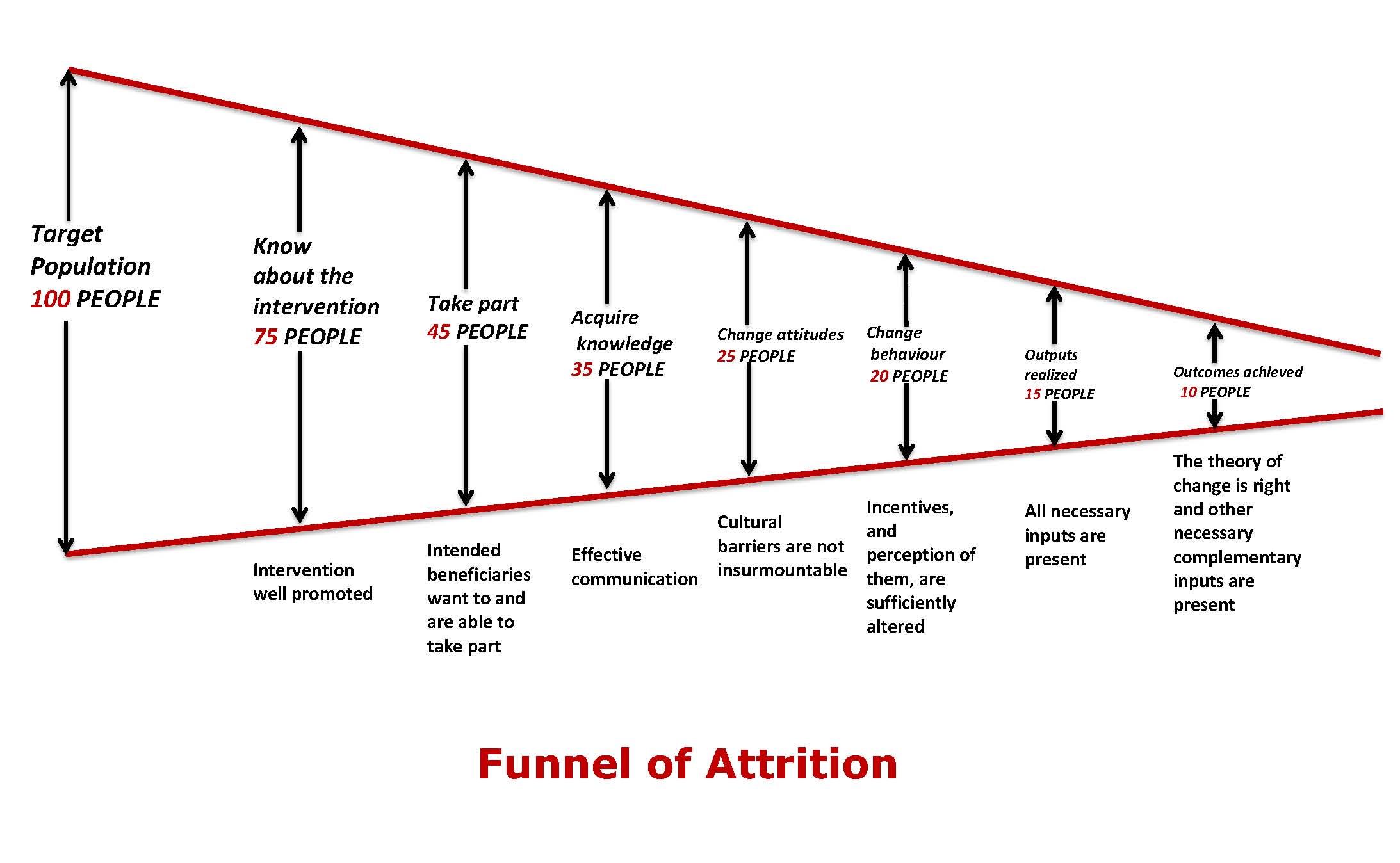
- Evaluating interventions that no one wants: Many impact evaluations fail because there is little or no take-up of the intervention. If 10 per cent or fewer of intended beneficiaries are interested in an intervention, then we don’t need to evaluate its impact. It will not work for more than 90 per cent of the intended beneficiaries because they don’t want it. The funnel of attrition is a tool that can help us understand low take-up and assess whether it can be fixed. But designers commonly over-estimate benefits of their interventions whilst under-estimating costs to users. So the programme that is implemented may simply be unappealing or inappropriate. Like point one, this point also relates to intervention design rather than evaluation. But this is an important point for evaluators to pay attention to since many of our studies examine researcher-designed interventions. And here again, a formative evaluation prior to the impact evaluation will give information on adoption rates, as well as the facilitators of and barriers to adoption.
- Carrying out underpowered evaluations: Studies are generally designed to have power of 80 per cent, which means that one fifth (20 per cent) of the time that the intervention works, the study will fail to find that it does so. In reality, the actual power of many RCTs is only around 50 per cent. So, an RCT is no better than tossing a coin for correctly finding out if an intervention works. Even when power calculations are properly done, studies can be underpowered. Most often, this is because it is assumed that the project will have a much larger impact than it actually does. So the true impact cannot be detected, and calculations are over-optimistic about adoption.
- Getting the standard errors wrong: Most RCTs are cluster RCTs in which random assignment is at a higher level than the unit at which outcomes are measured. So, an intervention is randomly assigned to schools, but we measure child learning outcomes. Or it is randomly assigned to districts, but we measure village-level outcomes. The standard errors in these cases have to be adjusted for this clustering, which makes them larger. We are therefore less likely to find an impact from the intervention. So, studies which don’t adjust the standard errors in this way may incorrectly find an impact where there is none. And if clustering is not taken into account in the power calculations, then an underpowered study with too few clusters will almost certainly be the result.
- Not getting buy-in for randomisation: The idea of random allocation of a programme remains anathema to many programme implementers. This is despite the many arguments that can be made in favour of RCT designs that would overcome their objections. Getting buy – in for randomisation can thus be a difficult task. Buy- in needs to be across all relevant agencies, and at all levels within those agencies. The agreed random assignment may fail if the researchers miss out getting the buy-in of a key agency for the implementation of the impact evaluation. Political interference from above or at the local level, or even the actions of lower level staff in the implementing agency can act as stumbling blocks to the implementation of random assignment. This leads to…
- Self-contamination: Contamination occurs when the control group is exposed to the same intervention or another intervention that affects the same outcomes. Self-contamination occurs when the project itself causes the contamination. Such contamination may occur through spillovers, such as word of mouth in the case of information interventions. It could happen if the people in the control group use services in the treatment area. But it can also occur when staff from the implementing agency are left with unutilized resources from the project area, so they deliver them to the control group.
- Measuring the wrong outcomes: The study may be well conducted but fail to impress policymakers if it doesn’t measure the impact on the outcomes they are interested in, or those which matter most to beneficiaries. Do women value time, money, control over their lives or their children’s health? Which of these outcomes should we measure in the case of microfinance, water, sanitation and hygiene interventions and so on? A common reason that important outcomes are not measured is that unintended consequences, which should have ideally been captured in the theory of change, were ignored. Prior qualitative work at the evaluation design stage and engagement with policymakers, intended beneficiaries and other key stakeholders can reduce the risks of this error.
- Looking at the stars: The ‘cult of significance’ has a strong grip on the economics profession, with far too much attention paid to statistical significance (the number of stars a coefficient has in the table of results), and too little to the size and importance of the coefficient. Hence researchers can miss the fact that a very significant impact is actually really rather small in absolute terms and too little to be of interest to policymakers. Where there is a clear single outcome of the intervention, then cost effectiveness is a good way of reporting impact, preferably in a table of comparisons with other interventions affecting the same outcome. Where researchers have followed 3ie’s advice to take this approach, it has sometimes reversed the policy conclusion derived from focusing on statistical significance alone.
- Reporting biased findings: Studies should report and discuss all estimated outcomes. And preferably, these outcomes should have been identified in the evaluation design stage. The design should also be registered, for example in 3ie’s Registry for International Development Impact Evaluations. Many studies focus unduly on significant coefficients, often the positive ones, discounting ‘perverse’ (negative) and insignificant results. Or even where there is no impact, the authors still conclude that the intervention should be scaled up, possibly because of publication bias or it is a researcher-designed intervention, or because they have fallen foul of the biases that affect traditional evaluations to favour the intervention.
- Failing to unpack the causal chain: Causal chain analysis is necessary to understand how an intervention was implemented and how and why it worked for whom and where. Researchers are often left to speculate in the interpretation of their findings because they have failed to collect data on the intermediate variables which would have allowed them to test their interpretation. The theory of change needs to be specified at the design stage; the evaluation questions need to be based upon the theory of change; and both factual and counterfactual analysis should be conducted to understand the whole causal chain.
{kind=link}
This list of pitfalls is not meant to stop researchers from doing RCTs or warn policymakers from using their findings. As I said at the outset, an RCT is a design that allows us to make the strongest conclusions about causality. But they fail to live up to their potential if they fall into any of the above ten traps of designing and implementing RCTs. So, let’s carry out better RCTs for better policies and better lives. How 3ie tackles these challenges will be the subject of a future blog.